Authentic holiday experiences are at the heart of HolidayCheck’s DNA. In this post, we would like to give you a brief glimpse of our various efforts to prevent fraudulent reviews from being published on our website. Emphasis will be placed on the overall review quality assurance process from a technical point of view.
Background
Reviews have always been the key component of HolidayCheck’s business model. They bring users to our platform and help them to find the right hotel. Nowadays, collecting reviews has become a competitive business, with many (travel) websites touting for users to submit their content to their platforms. At the same time, hotel owners have come to realize that good ratings can directly be translated to better business.
While the best way to get good reviews is to ensure a great experience at the hotel and set the right expectations upfront, some hotels try to boost their ratings with a shady approach. They put more effort into artificially varnishing their public appearance, rather than investing the time to actually work on their shortcomings. This demand has created a whole industry behind fraudulent reviews (beyond the travel segment), which focuses on generating authentically looking assessments. As these professional fraudsters also constitute the biggest challenge for our fake detection system, we will focus on their more sophisticated approach to submitting fraudulent reviews.
To guarantee authentic reviews on our platform our main goal is to be ahead of the fraudster’s game. To this end, we pursue a hybrid quality assurance approach. Its aim is to combine the strengths of state-of-the-art machine learning (ML) methods with the intuition and cognitive abilities of humans (i.e., our diligent colleagues in the content quality assurance (CQA) department. The purpose of the ML component is twofold:
It serves as a gatekeeper for incoming reviews to automatically classify them into potential fake candidates and genuine content.
It enriches the (meta) data on reviews with useful information that helps our CQA colleagues to manually assess whether the automatic classification looks valid and what next steps need to be taken.
Hence, our ML component focuses on two aspects:
- train a classifier that predicts fraud previews as accurately as possible, and
- provide information about which features were most relevant for making this classification (explainable ML).
In what follows, we will give a brief overview of both components.

Schematic overview
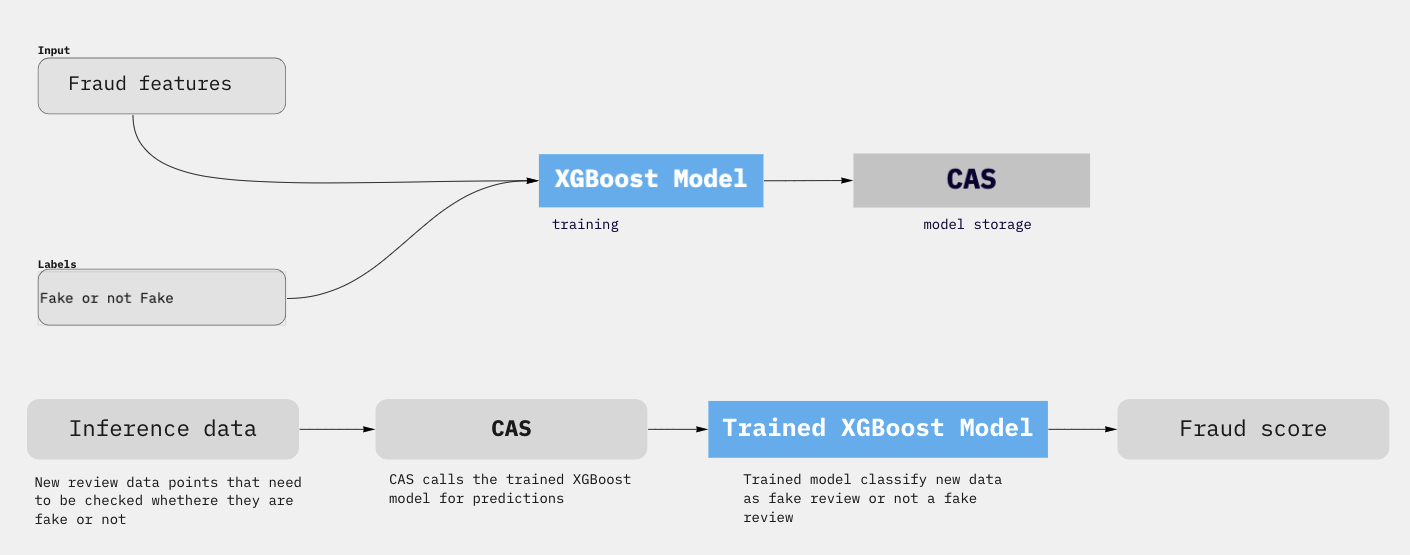
The actual features of the ML model are a well-kept secret of our internal fraud detection system that we cannot describe in public. They have been deduced from our long-term domain knowledge and careful analyses of fraud networks. The features along with the target data are used to train a XGBoost machine learning model. The trained model is stored separately from the CAS (Content Automation System) machine and can be updated without rebuilding the system. The purpose of the CAS component is to process the incoming reviews and thus to keep the ML component and the and the rule-based logic separate. The trained model is kept updated to adapt to new fraud patterns that develop over time. Altogether, there are more than a 100 features, although not all of them are equally important for the final assessment.
Fraud classifier (XGBoost)
As our classification problem can be described in terms of structured data, we opted for the Gradient Boosting method. We use the popular XGBoost open-source library for the actual implementation of the ML algorithm as it offers several additional benefits out of the box. Additionally, we utilize auto hyperparameter optimization (hyperopt) during the training phase. Since our classification problem is characterized by imbalanced data (fake reviews are much rarer than authentic reviews), we evaluate the model performance with the precision-recall area under the curve (PR AUC).
For the inference step, any incoming review is directly processed and classified by the ML model. The model’s score is forwarded as one piece of information for the manual CQA checks. Together with additional evaluations, such as language detection, text analysis and various business logic checks, the classification score thus serves as the key information whether an incoming review is additionally scrutinized by our CQA team and alters the review status ID accordingly.
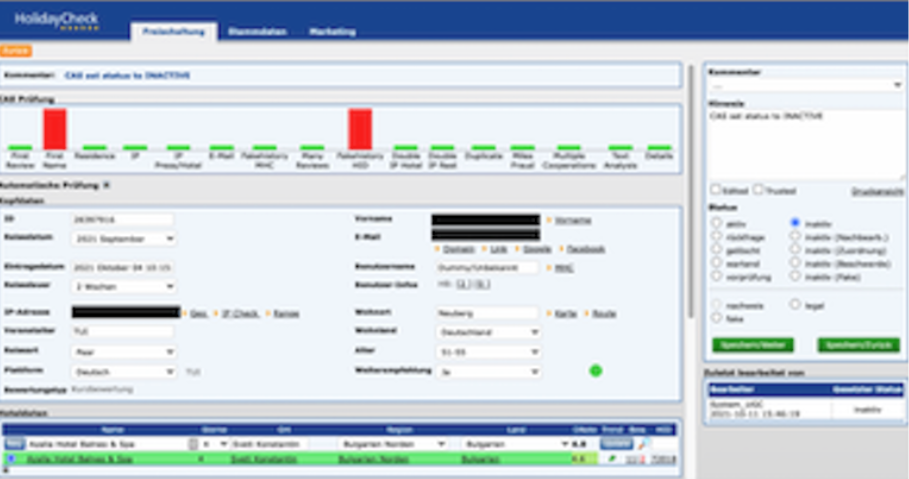
All information is then stored in the CQA Admin database and can be monitored by our CQA colleagues in the PHP Admin tool. While some data is easily interpretable through binary flags (the green and red bars in the screenshot below), some hints require more experience on the side of the manual checker to connect the dots. However, our automatic processing and overview reduces the amount of time to manually examine the fraud candidates by 70% and thus helps us tremendously to scale the overall review process.
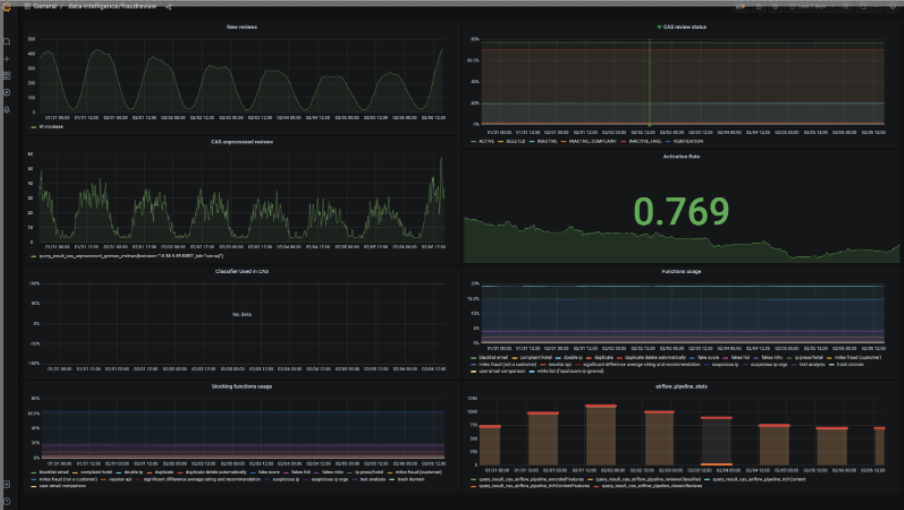
Behind the scenes, we closely monitor the model performance in a Grafana dashboard (see screenshot below). It allows us to quickly identify and react to any emerging issues. The dashboard also possesses a specific overview of which features of the model are mostly responsible for classifying incoming reviews as fake.
Shap values for explainability
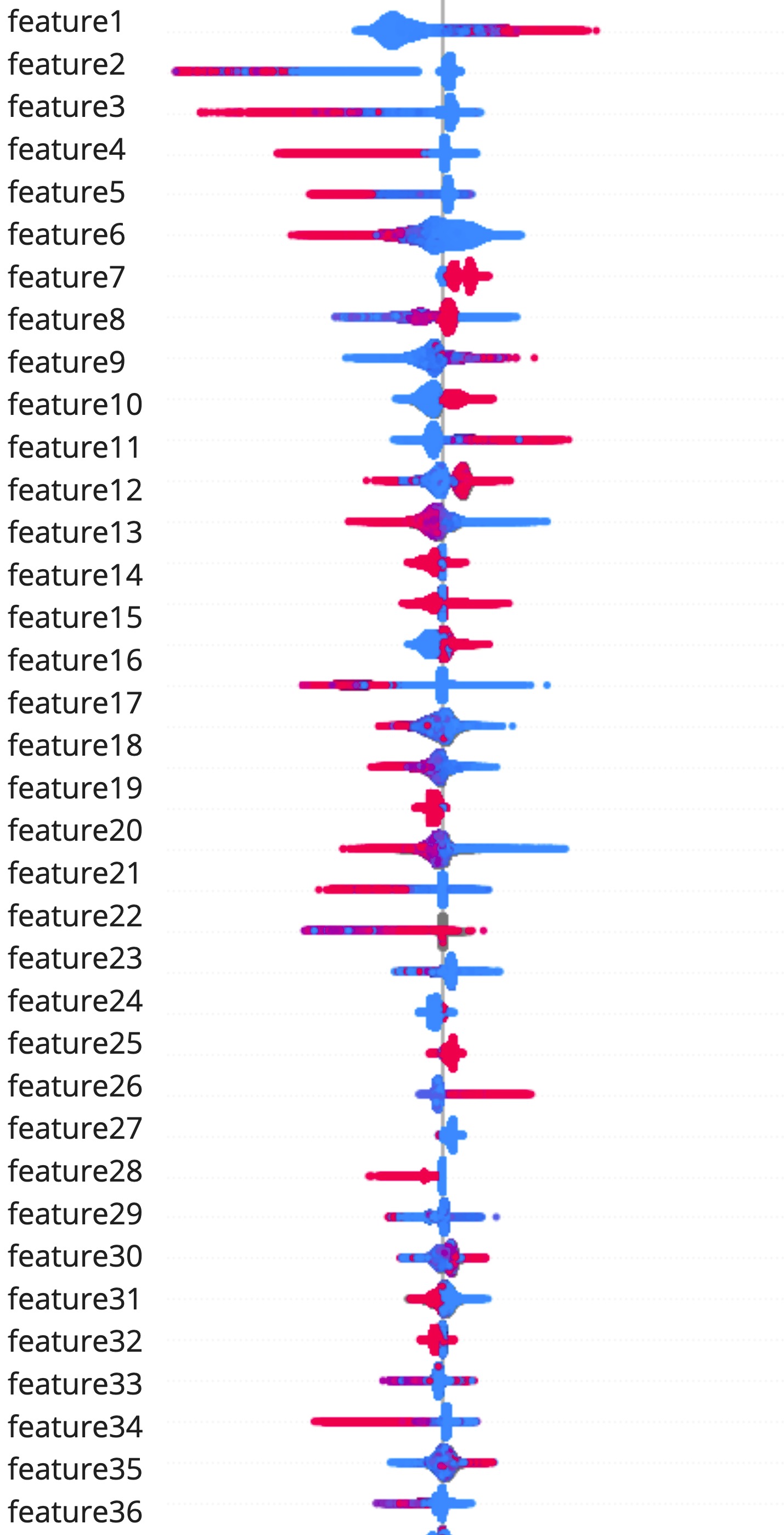
On top of the more rule-based flags that are based on our vast domain knowledge, we also employ a more thorough analysis of the model classification with the help of SHAP Values (an acronym from SHapley Additive exPlanations). We use the popular open-source SHAP library to deduce the model explanations. In the screenshot below, you can see a subset of the model features in a bee swarm visualization with their respective SHAP explanations. Unsurprisingly, there is a higher likelihood of fake when we have encountered a number of fraudulent reviews for the hotel in the recent past (feature 1). This feature is also at the core of our approach to detecting fraud networks.
Results
In this section, we want to focus on the second purpose of our ML system mentioned above: helping our CQA colleagues to easily assess incoming reviews. Without the fraud detection system, a full manual check of a review would take about 10 minutes on average. At the volume of incoming review content, it would require 100 full-time employees to check all reviews, not even counting staff for training/hiring and managing this workforce. Instead, with the help of our fraud detection system we could reduce the average processing time to under 3 minutes. Combined with the fact that we are successful in keeping the rate of auto-processed reviews constantly at a high number, we could significantly reduce the costs of manual work while keeping the quality of the detection on the same level or better.
Conclusion
At HolidayCheck, we want to do our best to guarantee authentic reviews on our platform. We have a lot of tools in our belt, but we need to continue working closely with our content quality assurance team to keep the fraud industry at bay. Close collaboration helps us to constantly spot areas where we can both still improve and support each other. We believe that our hybrid fraud detection system makes HolidayCheck’s quality assurance approach unique in the travel industry.